
全球產業正面臨前所未有的人力短缺和高齡化挑戰,從製造業、物流業到日常服務,各領域對高效能自動化的需求日益迫切。在這樣的背景下,人形機器人的發展是解決勞動力危機的解方,而運用VLA模型的實體AI將是機器人能再創新突破的關鍵。
VLA 模型賦予機器人感知、理解與行動的能力
調研機構Research Nester與GII的分析報告皆指出,未來5年全球人形機器人市場呈強勁成長趨勢,年複合成長率可達30%。這是由於人形機器人突破傳統工業機器人的限制,工業機器人雖然效率高但它們只能依固定程式碼運行,難以適應多變的生產環境。每當工作流程或產品更換時,工程師需要耗費數週甚至數月的時間重新寫程式,這種僵化的自動化模式,無法滿足現代社會對靈活性和快速部署的要求。
為了讓機器人從工具升級為能理解意圖並自主行動的協作者,近期產學界推出視覺-語言-動作模型(Vision-Language-Action Model,簡稱 VLA)。VLA 模型是實現實體 AI(Physical AI)的關鍵,它將人類的自然交流方式——視覺(感知)、語言(理解指令)和動作——整合到統一的AI框架中,使機器人能夠突破傳統的程式開發限制。
VLA 模型的突破在於其強大的通用能力和單次示教(One-Shot Teaching)的潛力。傳統機器人需要數千次的重複訓練才能掌握一項技能,然而藉由VLA 模型,工程師或產線工作人員只需要向機器人示範一次或口頭描述一次新的任務,VLA就能結合視覺輸入和語言理解進行推理,並自主完成該任務所需的動作。這種快速學習的能力,能將新任務的部署時間從數月縮短到數分鐘,大幅提升工廠效率和靈活性。
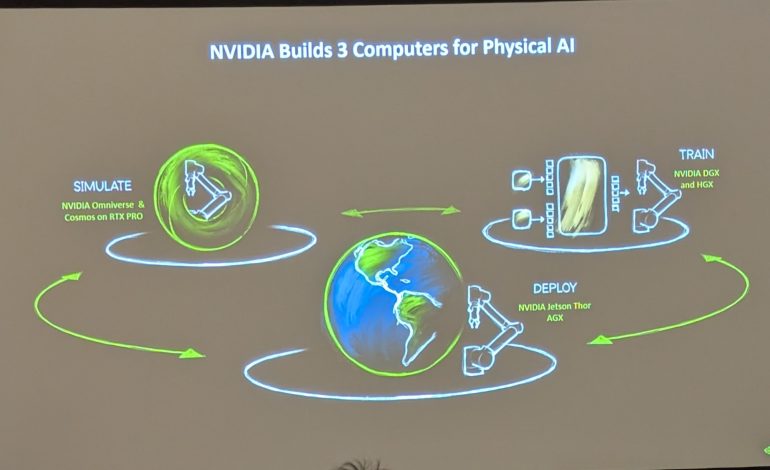
實體AI是新焦點 NVIDIA 用Omniverse 解決機器人資料不足問題
NVIDIA在上個月的Semicon Taiwan 2025亦提到近期推出的VLA模型,NVIDIA資深經理Andrew Liu表示,從生成式AI、代理AI到實體AI,實體AI將是產業下一波的焦點,NVIDIA致力於建造運用實體AI的AI工廠,其策略圍繞兩大核心支柱:機器人進階的基礎模型與精準的模擬環境。
要訓練出具備高可靠性的VLA模型,需要大量的真實世界數據,然而在現實環境中機器人的數據並不多。NVIDIA的解決方案是利用Cosmos平台及數位孿生平台 Omniverse,它能創建出與真實世界一樣精確、照片級真實的虛擬工廠和環境,藉此快速模擬各種場景並生成合成數據,用來訓練機器人及進行無數次試錯和驗證。如此一來不僅缺工問題有解,也可協助供應鏈快速複製工廠及擴廠。
VLA 模型的推出,預示著機器人將從簡單的重複執行者,轉變為能夠理解人類意圖、快速學習並適應多變環境的智慧夥伴。這不僅是技術的革新,更是應對全球人力短缺、推動產業進入更高生產力時代的關鍵動力。
- 首圖攝於Semicon Taiwan 2025 高科技智慧製造論壇






