
為何HBM記憶體在AI時代如此重要
人工智慧(AI)的飛速發展正在重塑全球科技格局,而高頻寬記憶體(High Bandwidth Memory, HBM)技術在這場變革中扮演著舉足輕重的角色。HBM憑藉其獨特的3D堆疊架構,不僅解決了傳統記憶體在AI應用中的瓶頸問題,更為大規模AI模型的訓練和推理提供了強大支持。
然而,隨著需求的激增,HBM技術也面臨著前所未有的挑戰。由於需要具備更高的製造精度,產能很難快速增加,而近期NVIDIA新一代AI晶片Blackwell B200因HBM相關問題可能延遲發貨的消息,正是這種挑戰的具體體現。
同時,在歐美防堵中國科技發展的風潮下,HBM也逐漸演變為影響全球科技競爭格局的戰略資源,變得奇貨可居。
HBM的技術優勢:3D堆疊架構的革命
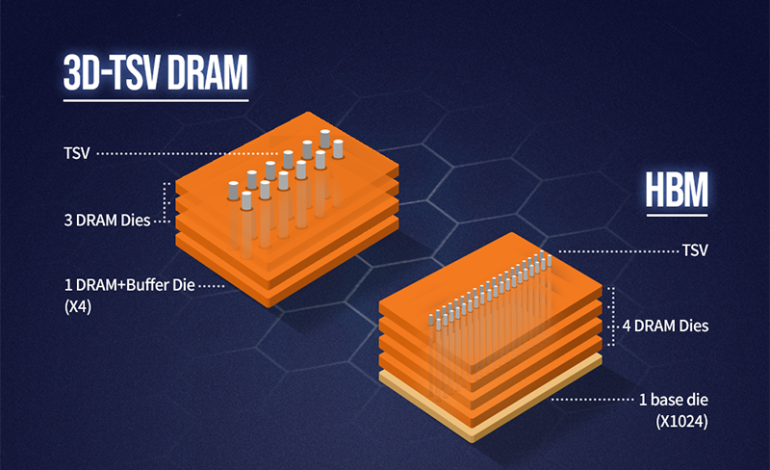
HBM技術的核心在於其獨特的3D堆疊架構。與傳統2D平面式記憶體不同,HBM將多個DRAM晶片垂直堆疊,通過矽穿孔(Through-Silicon Vias, TSVs)技術實現高速互連。這種設計大幅提高了記憶體頻寬,同時降低功耗並縮小晶片面積。
由於深度學習模型需要處理海量資料,進行大規模矩陣運算,這要求記憶體能夠快速、持續地提供大量資料。傳統記憶體架構在這方面往往成為瓶頸,導致AI處理器無法充分發揮其運算能力。HBM技術恰好解決了這一問題。
以最新的HBM3E為例,其頻寬可達8Tbps,是傳統DDR5記憶體的10倍以上。這意味著AI處理器可以在極短時間內讀取大量訓練資料或模型參數。
具體來說,HBM通過多通道並行訪問和超寬資料匯流排,實現了超高頻寬。例如,一個典型的HBM堆疊可能包含4-8個記憶體裸晶,每個裸晶有多個獨立通道(如8個或16個)。這些通道可以並行工作,大大提高了資料傳輸效率。同時,HBM採用的超寬資料匯流排(如1024位元或2048位元)遠超傳統DRAM(通常為64位元),使得每次資料傳輸的容量大幅增加。
在現代AI系統中,HBM直接與GPU或AI加速器整合在同一封裝內,通過矽中介層(interposer)實現超高速資料交換,成為AI處理器的理想搭檔。這種緊密整合不僅縮短了資料傳輸路徑,還顯著降低了訊號干擾和功耗。對於需要大量資料移動的AI工作負載,如大型語言模型的訓練和推理,HBM的高頻寬和低延遲特性可以顯著提升系統性能,減少資料等待時間,從而充分發揮AI處理器的運算能力。
HBM在AI晶片中的關鍵角色
HBM與AI處理器的緊密整合不僅縮短了資料傳輸路徑,還顯著提高了系統整體效能。以NVIDIA的最新AI晶片GB200為例,它採用兩個Blackwell GPU和一個Grace CPU,配合HBM3E記憶體,實現超過1TB/s的記憶體頻寬,為複雜AI模型的訓練和推理提供強大運算能力支持。
然而,HBM的複雜性也為AI晶片開發帶來挑戰。NVIDIA的Blackwell B200晶片因HBM相關的設計問題可能延遲發貨。根據報導,在連接兩個Blackwell GPU的裸晶上發現設計缺陷,可能導致晶片良率或產量降低,突顯其對整個AI產業發展的影響。
HBM的供需現狀與挑戰
HBM已成為高階AI晶片的標準配置,但其生產面臨諸多挑戰:
- 製造工序複雜:需要精確的3D堆疊和封裝技術,導致良率較低,成本較高。
- 產能限制:擴張受限於先進封裝技術如台積電的CoWoS-L產能。
- 供應鏈集中:全球僅有少數廠商掌握核心技術,增加供應風險。
儘管如此,SK海力士、三星電子和美光科技等主要記憶體廠商仍在積極擴產。SK海力士預計HBM需求將以每年82%的速度增長至2027年,台積電計劃到2025年將CoWoS產能提升近一倍,目的就是要解決目前AI生態的產能瓶頸問題。
HBM:從關鍵技術到戰略資源
HBM技術的重要性已超越純粹的技術層面,成為影響全球科技格局的戰略資源。在當前全球科技競爭背景下,HBM技術的掌控權已成為各國角力的焦點。特別是對中國而言,由於美國的出口管制,可能面臨無法獲得先進HBM技術的風險,可能會(potentially)阻礙其AI產業發展。
因此,中國正加速推進本土HBM技術研發,如長鑫存儲(CXMT)等企業已開始HBM的量產。然而,考慮到HBM技術的複雜性和產業鏈的完整性要求,中國要在短期內實現技術突破並不容易。
隨著AI技術的不斷演進,HBM已經成為AI時代最重要的記憶體技術之一,目前要解決記憶體傳輸的瓶頸問題只能靠它,在Jim Keller所謂不需要HBM的AI晶片真正面市,並被驗證具備可用性之前,它的重要性只會與日俱增。
照片來源:SK 海力士






